屏幕截图 2022-07-16 213240.png (162.52 KB, 下载次数: 23)
下载附件
示例程序1
2022-7-17 21:41 上传
屏幕截图 2022-07-17 213922.png (17.21 KB, 下载次数: 31)
示例程序2
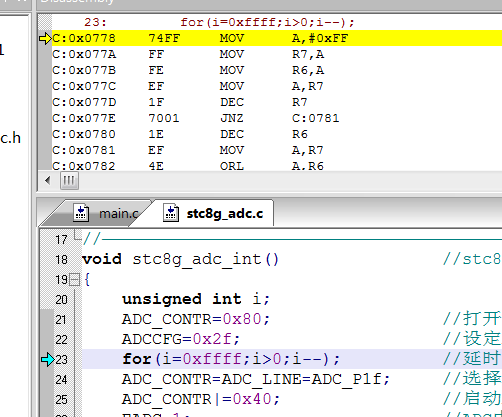
Hephaestus 发表于 2022-7-18 02:12 这就是CISC和RISC体系的区别了,CISC围绕着一个ACC来运转,RISC围绕一堆寄存器文件来运转,并不需要经过ACC ...
51hei截图20220718120803.png (26.87 KB, 下载次数: 27)
2022-7-18 12:18 上传
zhxiufan 发表于 2022-7-18 14:35 A累加器就好比交通枢纽,南来北往东去西来都得经过这里,所以大部分指令都需要借助这个枢纽到达彼岸。