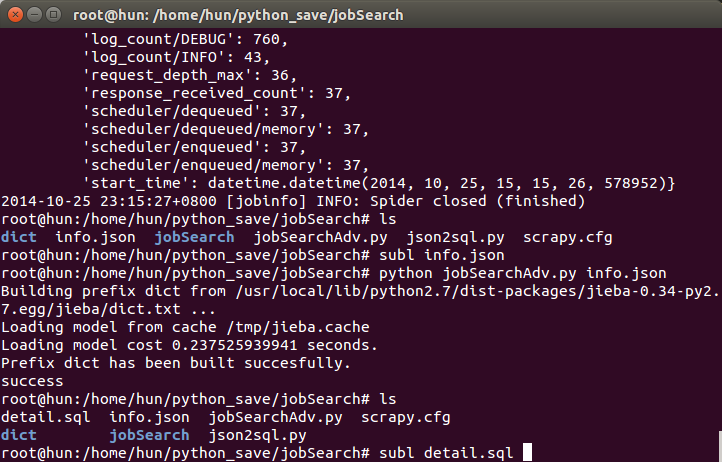
#read info.json to get the big data
def readJSON(fname):
with open(fname) as f:
for line in f:
data.append(json.loads(line))
data.sort(reverse=True)
#to find the keywords
def findKeywords(data):
jieba.analyse.set_stop_words("./dict/stop_words.txt")
jieba.analyse.set_idf_path("./dict/mydict.txt.big")
# jieba.analyse.set_idf_path("myidf.txt.big")
for i in range(len(data)):
try:
detailURL=urllib2.urlopen(data['detailLink']).read().decode('gbk')
detail=re.findall(u"标 题: (.*?)--", detailURL, re.S)
tags=jieba.analyse.extract_tags(detail[0],10)
data['keywords']=", ".join(tags)
except:
data['keywords']="?"
continue
readJSON(file_name)
findKeywords(data)
subdata="\r\n"
for item in data:
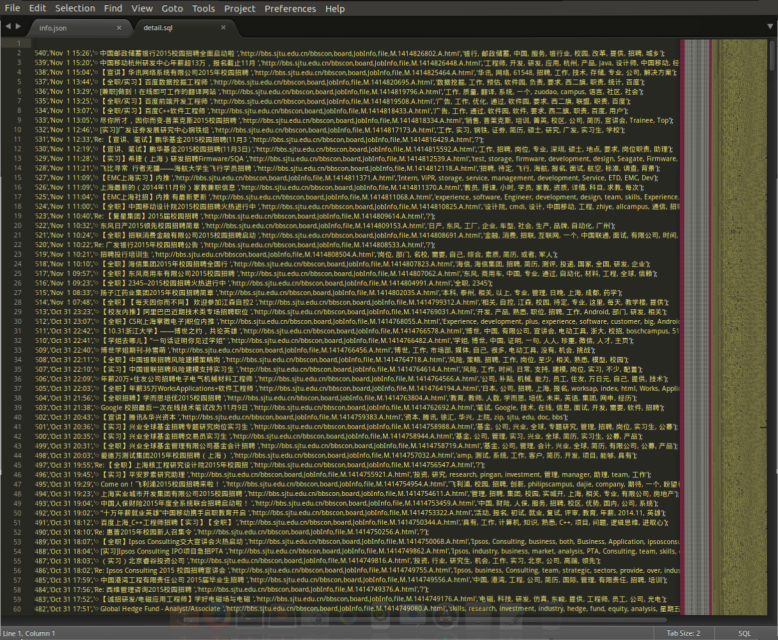
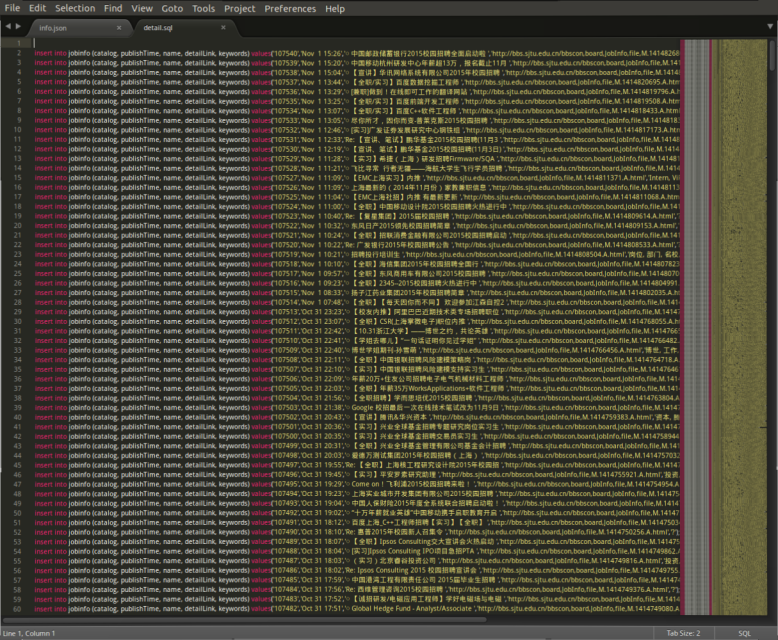
subdata+="insert into jobinfo (catalog, publishTime, name, detailLink, keywords) values"
subdata+="('%s','%s','%s','%s','%s');\r\n" %(item['catalog'], item['publishTime'], item['name'], item['detailLink'], item['keywords'])
file_object=codecs.open('detail.sql', 'w', encoding='utf-8')
file_object.write(subdata)
file_object.close()
print "success"
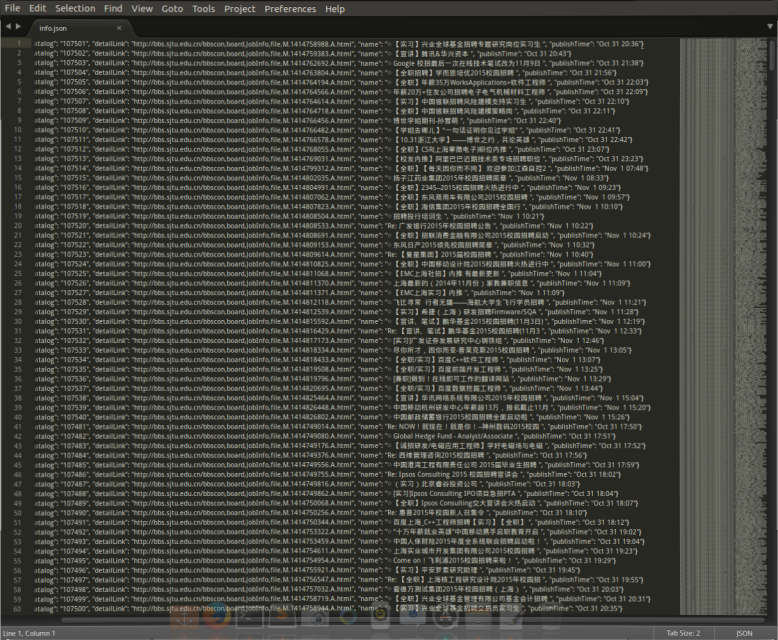
3)在python_save/jobSearch/jobSearch下编写items.py:其中catalog为信息编号,publishTime为信息发布时间, name信息标题 ,detailLink详细链接,keywords为关键词。
class JobsearchItem(scrapy.Item):
# define the fields for your item here like:
catalog = scrapy.Field()
publishTime = scrapy.Field()
name = scrapy.Field()
detailLink = scrapy.Field()
keywords = scrapy.Field()
 。最近又要交个无题的作业,加上前不久学长都在某某论坛里看就业信息,所以一来劲就做了个就业信息挖掘机。
。最近又要交个无题的作业,加上前不久学长都在某某论坛里看就业信息,所以一来劲就做了个就业信息挖掘机。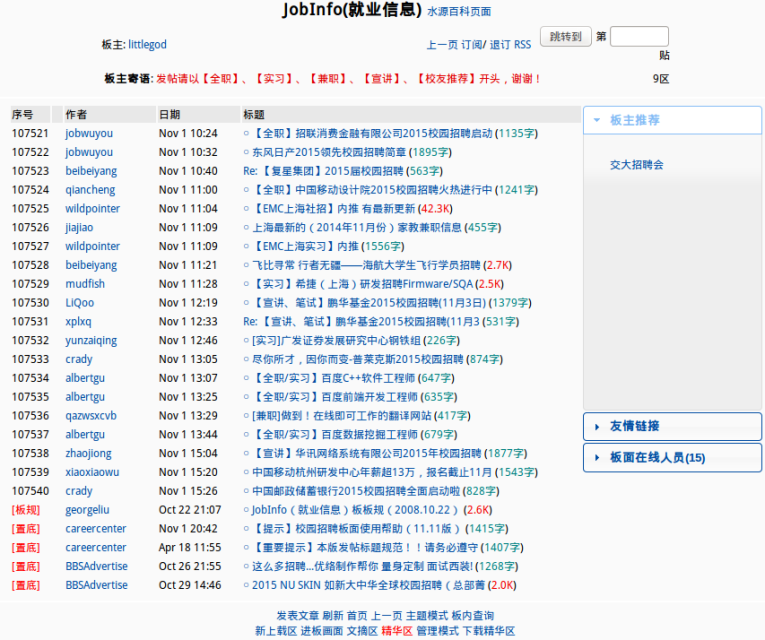
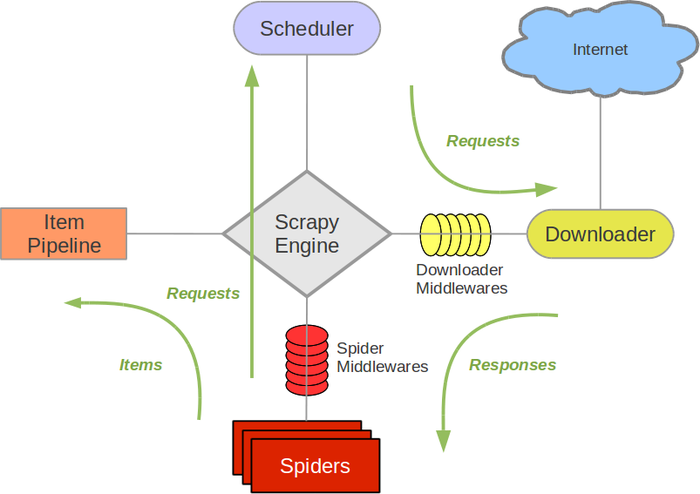
 当然这也仅限为思路,说说的。
当然这也仅限为思路,说说的。