GLIB散列数据结构浅析
一.散列表的基本概念
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
二.散列函数【hash function】的构造方法
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位,常用的构造方法有:
1 直接定址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a??key + b,其中a和b为常数(这种散列函数叫做自身函数)
2 数学分析法
3 平方取中法
4 折叠法
5 随机数法
6 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p, p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词
像第1种方法,要求关键字集合和地址集合具有相同的大小空间,一般用于数据记录不多的情况;第6种方法则不同,一般情况下,地址集合所占用的空间明显小于关键字集合,因此适合于大量数据的情况,但是它会带来一个现象,即存在着多个关键字对应着一个地址,这种现象用专业术语来讲叫冲突。
三.处理冲突的方法
1 开放定址法;Hi=(H(key) + di) MOD m, i=1,2,…, k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列三种取法:
1) di=1,2,3,…, m-1,称线性探测再散列;
2) di=1^2, (-1)^2, 2^2,(-2)^2, (3)^2, …, ±(k)^2,(k<=m/2)称二次探测再散列;
3) di=伪随机数序列,称伪随机探测再散列。
2 再散列法:Hi=RHi(key), i=1,2,…,k RHi均是不同的散列函数,即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间。
3 链地址法(拉链法)
4 建立一个公共溢出区
其中关于开放地址法和拉链法的介绍请参考博文:http://hi.baidu.com/zkheartboy/b ... 9296159f3d0.hta> 。在Glib中,对hash冲突处理采用了第3种“拉链法”来处理,下图所示。
四.Ghash表总体结构
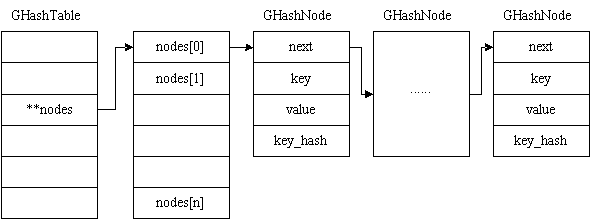
|






