本文作者为 Neil Lawrence,谢菲尔德大学机器学习和计算生物学教授。在
ODSC East(Open Data Science Conference East:开放数据科学大会(美国东部))上他详尽地探讨了机器学习的问题。
机器学习是一种数据驱动的人工智能研究方法。AlphaGo 通过许多局的自我对弈和观察大量专业棋手的对弈历史记录来学习怎样下围棋。
看起来,让计算机成为世界上最好的围棋手只是一个时间问题。AlphaGo 通过机器学习击败了欧洲围棋冠军,这项技术是近来计算机视觉、语音识别和语言翻译等人工智能领域内的重大进步的基础。
最终的结果,当 AlphaGo 和那位欧洲围棋冠军开始第一场比赛时,它所下过的棋局数量就已经远远超过了任何人一辈子可能下过的棋局数量。自从那次获胜之后,AlphaGo 还一直在积极学习提高自己。它日夜坚持不停地下棋,努力为与世界冠军的对战做准备。
我们的数据错觉
[size=1em]这一现象并不仅限于 AlphaGo。在其它领域,我们(系统的)人类级别表现也受惊人的庞大数据驱动。我们的视觉系统为了识别物体需要远比我们所需更多的有标记图像,我们的语音系统为了理解话语需要远比我们所需更多的话语,我们的翻译系统需要的已翻译样本比一个人类能够阅读的还多。 [size=1em]
[size=1em]
△世界数据能力的增长评估
所以,尽管我们正在一些曾经被认为非常困难或不可能的任务中取得可观的进步,但事实是这些进步更多是由更多的可用数据推动,不是来自算法的进步。事实上,当我们首次尝试解决诸如物体识别和语言翻译这样的任务时,如果试图将最新方法应用到那时拥有的数据量上,这些任务不可能得到解决。是数据爆炸让它们易于处理。
蒸汽
[size=1em]这种情况让我想起了工业革命的早期阶段。Thomas Newcomen 生于英国西南部——一个自罗马时代以来就以锡矿闻名的地区。矿需要将水抽出去使采矿不被影响。 1712 年,Newcomen 发明了蒸汽机来做这件事。他发明的引擎由一个位于锅炉顶部的大型活塞组成。锅炉产生的蒸汽交替填充这个活塞,然后通过直接注入水进行冷却,进而引发运动。 [size=1em]
[size=1em] 煤炭
[size=1em]刚使用的时候,Newcomen 的引擎在他当地的锡矿里只有相对很小的作用,如此低效以至于毫不实用。但是,它们却在煤田中得到了广泛的使用,因为在煤田里可以很容易补充燃料。这多少让我想起今天的情形:主要互联网公司可以通过当前一代推理引擎获利,因为这些公司相当于当年的煤田,拥有大量可供使用的数据。 [size=1em]
医疗应用
[size=1em]目前,我们正在错失(这一领域的)锡矿以及任何其他矿藏的等价物。在医药等应用领域,我们面临不少困难,首先是因为:系统的复杂性远远高于语音、视觉、甚至围棋游戏。我们的干预通常是在生物化学层面,然而,干预的临床表现却发生在全球健康层面。
对于罕见或复杂的疾病——那些由坏境和基因原因共同导致的疾病,使用当前这套低效模型,我们将永远不会获得足够的数据,让这些复杂模型学习早期诊断和治疗所需的知识。
分离冷凝器
[size=1em]在我们脑海里,蒸汽机与詹姆斯·瓦特的相关度要高得多,瓦特通过引入分离冷凝器让蒸汽机变得实用。他没有直接将水注入到汽缸中,而是将蒸汽吸出汽缸后分开冷却它。 [size=1em]
[size=1em] [size=1em]△詹姆斯·瓦特带有分离冷凝器的蒸汽机的结构 [size=1em]
[size=1em]这种设计更加有效,因为汽缸本身再也不用经历加热和冷却的循环了。由此导致了效率的倍增,使蒸汽机变得实用;它不再只被用于康沃尔的锡矿,也被用在了铁路和牵引引擎上。 [size=1em]
智能
[size=1em]我对智能的定义是:使用信息,节省能源。
智能决策的含义是,消化事实,做出决定,这个决定减少了与行动相关的支出(较之没有掌握哪些事实的情况下)。根据这一定义,通过生成决定节省能源或者使用更少的信息,我们就能变得更加智能。
在非常现实的意义上,目前还存在数据效率赤字问题,赤字和当年 Newcomen 的引擎效率赤字一样大。机器学习需要它的分离冷凝器这一契机。在数据效率上,我们需要一次瓦特的分离冷凝器一样的革命。 [size=1em]
函数组合(Function Composition)和深度学习
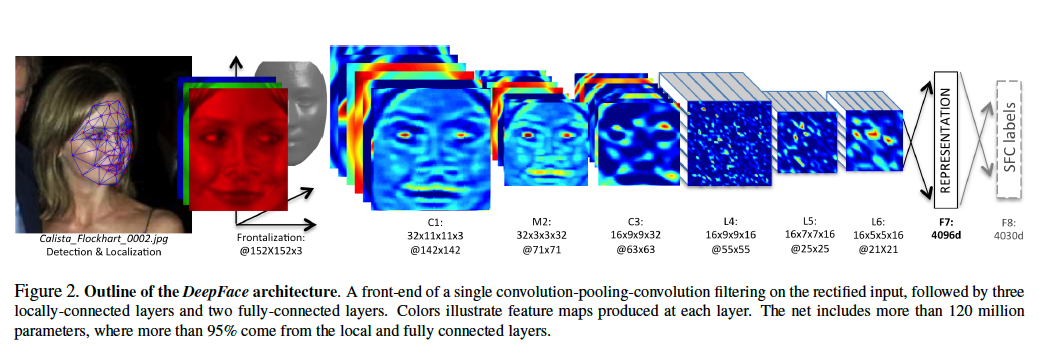 △DeepFace 的架构,该识别系统来自 Facebook 的论文
△DeepFace 的架构,该识别系统来自 Facebook 的论文[size=1em]
[size=1em]在数学上,我们有时候可以将一个函数看作是一个确定过程(deterministic process)。因此,我们能将深度学习视为确定过程的组合。每个过程组合起来,创造出更加复杂的过程。对过程呈现数据(presentation of data to the process)能让我们运用一组转换获得一个结果。上面的例子来自于 Facebook 的DeepFace 算法,其目标是区分所给图片是否是 Calista Flockhart 的脸。
[size=1em]
在机器学习中,这被称为深度学习。对于一些作者而言,这与大脑有关或是一种思考人工智能的基本方式,但是,我们可以简单将其看做是一种明智的想法,将一系列简单变换运用于图片,构建复杂转换。
现在机器学习的难题是怎么决定这些转换的应该是什么样的。每一个更简单的确定转换,确实可以有许多参数。在 DeepFace 的案例中总共有超过 1.2 亿个参数。
当我们想到深度学习时,就能想到任何给定数据点通过决定过程,就像小球穿过早期的弹球机(Pachinko 机)。每一层的栏针等同于深度模型的每一层。 [size=1em]

△弹球机
机器学习的目的是重构这些栏针的配置,使 Calista 的脸可被正确探测到。可以将脸看作是以一组初始条件,而脸通过每一个过程后都以修改过的形式出现。推理的任务是确保正确的初始条件集合能导向正确的结论。
我们的深度学习模型就像 Pachinko 机,但我们所能控制的只是栏针的位置。深度学习的目的是移动这些栏针的位置使其在正确的初始条件集合下(如我们比喻中的图像所示)可以得到正确结果。
该模型的参数有时被称作是网络权重(network weight)。它们就像是栏针的位置。所以我们可以将 DeepFace 看作是有 1.2 亿个栏针的 Pachinko 机。
我们可以将网络关于某个特定模式所「想到」的内容看作是小球穿过网络时的左右位置。当然在现实中,在栏针的每一层,这个「想法」只有一个值。它是一维的。真正的深度网络拥有许许多多的维数,所以它就像一台栏针位于高维空间的 Pachinko 机,通常这被称作超维空间(hyper-space),这意味着该网络的「想法」有更高维数而且更为复杂。
确定过程
今天占主导地位的技术假定,球应该通过固定的路径通过网络。球在弹珠机任意层的位置被称为该层的激活。当球落下时,栏针决定了它的位置。在理论上,我们可以精准地说出球在任何时间的位置,因为弹珠机的每层都只涉及一个球撞击栏针:这是一个确定过程。
弹珠机的游戏包括试图通过用正确速度使用柱塞开球来赢得高分。这很难做到,因为分数对起点的位置非常敏感。但实际上,这场游戏是「理解」球的初始速度,并通过给它打分数来分类。
面临的挑战是优化机器的内部结构,使它在正确的初始条件下给出正确的答案 (或标签)。然而,要做到这一点,需要探索我们想要测试的全部初始条件:并且针对数量肯定会很多的图片。
卷积神经网络 (convolutional neural networks) 的巧妙部分是为机器建构第一组层级,使诸如图片中「不变性」的这些方面更加容易学习。 不变性是指在图片里,不论旋转还是移动,一张脸都是相同一张脸的概念。我们的大脑很容易明白这点,但不变性很难被电脑理解。深度神经网络则通弹球机第一部分结构的巧妙设计来实现这一点。
绝大多数学习的方法是,在弹球机的顶部呈现一个图像,看球在哪里弹出。如果球在错误的地方弹出,所有的栏针将稍作移动,试图让球多出现在正确的位置。
问题
如果你用各种不同存在微妙变化的方式扔球,这个方法会很好用。你最终可以让系统正确。但是,如果你只有有限的扔球次数,怎么办?
你已经知道,输入值的微小变化可以解释终端相当大的变化。弹球机很复杂,并对输入值的微小变化敏感。但是,要正确确定这些敏感点需要大量的数据。
另一种方法是,确保机器对初始条件的小变化保持强健 。做到这一点需要随机性。不要把机器建模为一组确定过程——其中球每次以相同的方式掉下,你要把机器建模成一组分层的随机过程 (stochastic processes) 。
接受在顶部扔球方式上的小变化,意味着我们其实不知道球在任何时间应该在哪,因为我们无法准确知道栏针的位置,或者球的初始状态。进一步,我们永远不会有足够的数据来探索不同所有这些不同的状态。
随机过程构成

我们通过考虑球在机器上所有可能经过的路径,获得更多有效的学习方法。不要鼓励机器只盯着一条路径,我们鼓励所有通往正确结果的路径。
考虑所有路径可以使模型对输入上的小变化上更健壮 (robust)。试想导航通过有许多不同路径的森林。这两种方法之间的区别就像是确保有一个标记完善,通往正确目的地的路径,或者有一组不同的路径带你去正确目的地。
这是一个系统的路径积分解释。我们设计了一个系统,在其中考虑所有球可能在系统中通过的路径。更奇怪的是,我们考虑了应该同时带你抵达那里的栏针的所有可能配置。
这听起来很困难,但在某一类过程中(例如高斯过程)中确实易于处理 。所以,如果我们用高斯过程做出每一层,就能处理那个组成部分本身。但是,我希望我们的深度模型有很多这样的层在一起,这样我们可以为复杂事情建模。要做到这点,我们组成随机模型:有效地将这些层再一次叠在一起,就像在弹球机里一样。当我们把简单的流程堆叠在一起,会有很多关于如何做数学并且执行相应的算法等挑战性的问题。
我们知道,对于非常大的数据来说,我们所提出的随机方法瓦解了深度学习的确定性方法。因为在这些情况下,路径积分瓦解成单个最有可能的路径,随着我们获得更多的数据,它也变得确定。但是,对于低数据(low data),我们可以实现更好的效率。
算法的挑战
主要算法挑战在于,路径积分解法(solution of the path integral)要比仅仅找到最佳路径要有挑战性地多。最佳路径仅需我们做出区分,但是,浏览所有路径需要集成,这是一个更大的挑战:特别是当在我们所需的Pachinko机的「超维空间」版本中执行这一操作时。这一数学操作就是所谓的卷积,而且也只可能针对简单系统进行精确操作。
前行之路
热动力学花了好长时间才跟上瓦特分离冷凝器的应用步伐,但是,完全理解热动力学却对现代世界的发展,至关重要。结果表明,我们实现高效智能所需的路径积分和热动力理论之间存在强数学关系,后者被用来解释为什么瓦特的分离冷凝器让蒸汽机引擎更有效率。
一个向前的数学方法被称为「变分法」。包括将不同积分转为不同但更加简单的优化问题。这个方法不是很准确,但是会时常比确定性方案要好得多。这被称为变分学习。如果我们建造有效的变分算法 ,就能在小数据集上实现深度模型。
最终仔细分析热能理论基础的也是变分方法。从这种研究中出现了一些概念,比如熵。
我们知道一件事,通过热动能的类比,最好让你的Pachinko机「尽可能地热」(或者,尽可能不确定)同时约束它按平均值给出正确答案。那会让它对输入的变化更加强健。物理学上,这一方法被称为最大熵原理。
下一代数学高效学习方法依赖我们研发出新算法,正好通过模型传播随机性或不确定性。
有一个大型并还在不断变大的研究人员社区,他们实现并推到这些算法。他们多采用数学的方法而不是标准的方法,不过,没有他们,我们当中的许多人会处在当年康沃尔锌矿工的位置:因为我们自己缺乏数据效率,因此无法受益于广泛的数据供应。
因此,最终,我们的效率要求归结为处理不确定的问题。瓦特的效率成果来自确保引擎活塞尽可能维持热度。因为关闭热蒸汽的活塞被吸出并分离冷凝。这能够让活塞热运行,传递必需的效率。
在深度学习的概率和随机方法上,我们必须施展同样的窍门。模型本身需要尽可能地维持热度:然后,当数据不足以约束拥抱不确定所需的模型的运行时,别熄灭它。当机器循环通过数据时,我们的分离冷凝机将允许学习机器中保持高温。那会确保运行合理方式的全部空间得到开发,并且我们的推理也会保持必要的强健性,即使当数据稀少时。
?本文由机器之心编译
| 





