基于vb做的vb试题组卷系统

全部资料51hei下载地址:
 VB058试题库自动组卷系统计算机毕业设计.rar
(552.88 KB, 下载次数: 32)
VB058试题库自动组卷系统计算机毕业设计.rar
(552.88 KB, 下载次数: 32)
目 录
摘要........2
英文摘要.2
第一章 引言 .......3
第二章 系统分析....3
2.1 试题库分析..3
2.2 组卷分析..4
2.3 系统简介..5
第三章 数据库设计....6
3.1 系统数据库..6
3.2 临时数据库..7
第四章 系统总体结构设计......8
第五章 模块设计及实现.......9
5.1 用户登录模块..9
5.2 系统维护模块....10
5.2.1 新建数据库...10
5.2.2 修改密码 ..11
5.2.3 添加用户11
5.3题库管理模块...11
5.4自动组卷模块...13
5.4.1 功能 ..14
5.4.2 设计思路14
5.4.3 组卷策略分析....14
5.4.4 代码实现....16
5.4.5 试卷编辑22
结束语23
参考文献...23
考试是教师检查学生学习情况的必要手段,但出卷却是一种繁重的智力和体力劳动,传统的标准化试卷命题,需要由教学专家组成一个命题班子,根据许多优秀教师多年的教学经验,从贯彻教学大纲要求,到试卷意图的组织,经过反复的推敲,才能完成一份标准化的试卷。这样的命题方式不仅工作任务繁重而且试卷的标准化程度、难易程度、题量大小等各方面难以控制,难以形成有效的试题库,给试题和试卷的管理带来很多问题和困难。鉴于这种情况,利用计算机进行试卷的自动生成并逐步积累形成有效的试题库,对试题和试卷的管理将变得高效而便捷,对提高工作效率,使试卷管理逐步走向正规化自动化将起到十分重要的作用。同时使出卷工作变得轻松愉快,从很大程度上减轻了教师利用传统的出卷方式组卷的繁重工作量,大大节省了老师的工作时间,便于教师有更多的时间和精力致力于教学方法的研究。今日, 随着计算机的应用的普及和硬件设备性能和软件制作水平的提高,为研制开发高性能的试题管理软件提供了条件。
作为在教学第一线的老师,往往需要及时了解学生对某一章节知识掌握的情况,经常需要对学生进行形成性测验和终结性测试,来发现教学中的问题,从而调整教学进度,改进教学方法。不少软件开发者看到了教育工作者在这一领域的需求相继推出了一批与试题管理有关的操作软件,其中不乏非常出色的作品。但是从试题管理这一方面来看,用户反应平淡,感觉中意的不多。我们不禁要问:为什么是这样的结局?老师们最需要的是什么呢? §2.1 试题库分析 在试题库方面,老师最需要的是对试题库管理的自主性。老师们渴望能自由地操纵试题库,具体表现在以下三个方面: (1)自主初始化试题库;
(2)自主维护试题库;
(3)自主设计试卷。 ※自主初始化试题库
即用户拥有创建新试题库的权力,用户能够根据自己的需要,设计试题的储存方案以及试题的属性名和各属性值,实现试题库用户个性化设计,让试题库真正成为用户自己的试题库。。用户不喜欢这一种不能自主控制的试题分类方案,用户希望自主地初始化试题库。 ※自主维护试题库
即用户具有添加、修改和删除试题的权力,实现试题库的可扩充性和开放性,使用户对试题库具有至高无上的支配权。现在已经推出的几乎所的试题管理软件都不具备这样的功能,用户所使用的试题被程序制作者预先写在某个文件中,这些文件不是隐藏得让用户难以找到就是经过加密处理,用户根本就不可能通过其它方式(比如Word、Access、WPS等)打开并看到它,更谈不上对它的扩充、修改和对某个试题的删除了。由于用户没有自主维护试题库的权力,新试题无法录入,陈旧试题无法删除,这样的试题库在较短的时间内就逐渐老化、失去活力。用户需要自主地维护试题库,希望及时地更新试题库。 ※自主设计试卷 现有的某些试题管理软件不仅不支持试题库中试题的修改,生成的试卷也不可以修改,连加一个空格修改字体都不行,试卷保存后不能为其它系统(比如Word、WPS等)识别,只能从打印机上输出,这种方案没有多少实用性。 试题库要保证一定的规模,给随机选择以较大的范围。建立题库是一个复杂的系统工程,首先要建立系统的数学模型,然后确定试题的属性指标以及试题的组成结构,再组织大批量的优秀学科教师编写试题,为了保证这些试题的科学性和有效性,对每一题试题进行抽样测试,对试题参数标注的有效性进行校正,建立起一个实用的题库系统,另外,应该对题库的管理实行一定程度上的开放性,以不断提高题库的质量和可维护性。建立题库是一项相当复杂的系统工程,不仅开发需要大量的人力和时间,而且还要花费相当的时间和人力物力去维护调整,才能真正在教育中发挥作用。 §2.2 组卷分析 一般地说,对题库系统组织试卷的要求是根据出卷者的需求产生一份对于测验目标(如教学评价、学生能力水平评价等)有价值的测验试卷。因此,在组卷时,用户要提出组卷要求,通常包括题目内容范围、题目类型、题目数量和测验目标等方面。这些要求应转化成试卷每个题目的量化参数才能被系统使用。例如按照测验目标各知识点内容所占比例数,各层次的目标(记忆、理解、综合、应用等)分别由哪些题型反映,每种题型在试卷中的数量,各难度级在卷中所占比例,难度等要求。量化工作可以由人工完成,然后按一定格式送入系统中。也可以由系统在一定程度上自动完成量化转换,形成相应的组卷参数。 要解决的一个首要问题是组卷策略的选择。它在很大程度上决定着系统的成败与否。组卷策略的实质是将对人比较直观明了的组卷参数变换成计算机能够直接操作的试题属性项,然后根据这些属性项,在题库中抽取试题组成试卷。因此,完整的组卷策略应该由三部份组成:试题属性项定义、组卷参数的定义、变换算法的说明。所谓计算机组卷至少应该保证以下几个方面的平衡方可考虑试卷的可接受性: a) 整卷的题型比例要合理 d) 要保证随机性 一种做法是,让出题者按照一定格式描述试卷编制计划信息,如卷内题目在题型和难度上的分布,知识点内容在各目标层次上的分布(包括数量),然后通过一定算法变换成试卷试题的具体要求。另外一种做法是将课程目标与内容信息在系统中建立一个目标/内容分布关系表。 在题库中按上述量化的组卷要求查找符合条件的题目进行出题组卷,一般都采用匹配方法。精确匹配可以组出完全符合量化标准的试卷,但有时会出现组卷策略无法实现的情况(即查不到完全符合条件要求的题目)。为了避免这种情况,设计组卷策略时要考虑怎样解决它。常用的办法之一是形成并试用新的组卷策略,这种做法会带来时间上的浪费。另一种办法是把精确匹配改成近似匹配。采用近似匹配时应事先规定所选题目在内容、目标、题型与难度等各指标上是否可以与出题要求不完全一致,能不能有一一定的模糊度。若模糊度为0表示必须精确匹配;而非零值则青示可有多大的变异度。在后种条件下,若找不到完全符合要求的题目,就可以在模糊度许可范围内查找近似匹配的题目。 §2.3本系统简介:基于以上诸因素的考虑,设计了本系统:本系统以高一的英语教育为背景进行设计,其意旨在于提供一个适合于形成性测试和阶段性测试的自动组卷系统。本系统能快速方便地提供各种要求的试卷,帮助教师把握教学的进度,及时地反馈教学中的问题,以改进教学方法和调整教学重点。 功能:本系统主要有2大功能模块组成:一,题库管理;二,自动组卷。具体的功能及实现将在后面做详细介绍。 特点:1.易用性:人机交互界面友好,不要求使用者具有太多的计算机知识 2.先进性:前端自动组卷+后端题库管理+优选试题 3.合理性:结合国家教材,符合教学大纲。 4.实用性:教师减负第一步,帮助教师从烦琐的出卷工作中解脱出来 实现工具:基于试题库的自动组卷系统即以强大的试题数据库作为后台支持,由于Access是目前比较流行的一种数据库软件,它允许并很容易地用多种方式进行筛选、分类和更新数据,因此本系统中采用Access来构建系统数据库。作为与用户做交互界面的前台,本系统采用Visual Basic 6.0作为开发工具,它具有丰富的控件、先进的ADO数据访问技术、数据报表输出技术等。
第三章 数据库的设计 数据库的库结构对于整个系统的性能起着重要作用。它是本系统的基础。一个题库将存放大量的题目,这些题目在计算机内如何存储将直接影响题库系统的工作效率和效果,因此题库结构的设计是题库系统设计开发的关键一环。题库结构设计时要考虑题库的基本特征。题库结构设计最基础的工作应包括确定题目类型、规定试题属性及题库总体数据结构的确立等几方面。题库是计算机辅助测验系统的基础。一个大的测验系统的题库应能容纳足够数量的题目,这些题目在题库中的组织、分类及其特征信息的确立与描述将直接影响系统的工作效率与效果。 本系统总共构建了2个数据库文件:系统数据库datadb和临时数据库temp。 §3.1 datadb 数据库 因为本系统是以英语教学为例,因此构建了一个用于存储英语试题及相关属性的试题数据库。在程序中设置别名为datadb。在该库中共建立了6张表,其表名分别为: a:选择题 b:完型填空 c:阅读理解 d:短文改错 e:书面表达 f:登录 ◘3.1.1 试题文件 a~e是对应于英语中常见的五种题型的试题文件表。为了通用起鉴,为每张表设置了相同的字段,依次为题号、分值、难度、章节分布、题目以及答案6个属性。 · 题号---整型,设置为主键,即为试题库中题目的编号; · 分值----整型,是该题的分数; · 难度----字符型,它的设置采用了3位编码:用三个数字来表示该题的难度。对于不同的表,它的含义略微不同。在完型填空、短文改错中,左起第一位、第二、第三位依次表示在该题中较容易、中等难度、较难得分的题目总分值(比如在完型填空中,有25小题,若每题为1分,则难度系数为988表示的意思为有9题是容易的题目,有8题为中等的,另外的8题是较难的题目),对于书面表达这种大题,没有小题的设置,则难度系数的含义稍有差异(若书面表达的总分为20分,则难度为875表示8分是比较容易得到的,7分是中等水平的学生才能获得的,而最后的5分则是较少部分的学生才能的到。)对于选择题而言,它每题的分值较少,因此不再对分值拆分,只在相对难度位置上出现该题分值,如100表示该题属于容易题,总分为1分,010表示该题为中等题。虽然各表中的难度属性的含义看似有上述的差异,但是对于表达难度这个概念而言,它们所能实现的功能是一样的,因此在程序中对于每个表中的难度做同样的处理。 · 章节分布----字符型。在该系统设计的过程中,通过对高一的英语教材的分析和研究,把整个年级阶段的知识点按教学进度划分为十个章节,用A~J表示,在A~J之后用数字表示的则是该章节中所涉及的细微的知识点。(001:虚词;010实词;011: 时态;100:语法;101:结构;110:语态;111:情景意境),比如某选择题的的章节分布为C110表示的是它所要考查的知识点是属于第三章中的语态。定义了总体上的A~J个章节,则可以在不同的教学时期,选择不同章节属性的试题来测试,以避免试题不适合教学进度的情况。之所以要对每个章节分开定义001~111等知识点,是因为由于教学进度不同,虽然是相同的知识点,但是在不同阶段对学生的要求是不一样的。 · 题目---备注型。这是在最终生成的试卷中真正要出现的部分。 · 答案---备注型。同题目的性质一样,但它们是分别输出到不同的文档中相互独立保存和打印的。 以上描述了存储五种题型的5张数据表中各个字段含义。接下来来介绍一下最后一张数据表---登录表中的属性设置。 ◘3.1.2 登录文件 该表中总共设置了三个字段属性---用户名,密码,访问次数。 · 用户名--字符型,是每条记录中的主键,值唯一,不能重复。数字、字母都可以。在系统的使用过程中,具有一定权限的管理员可以对其进行删除和增加。 · 密码--用于核准用户的权限,避免一些不合法的人进入系统进行破坏活动。 · 访问次数--整型 用来显示该用户已经使用过本系统的次数。 §3.2 tempdb数据库 其中只有一张数据表—temp。它用来存储在抽取试题过程中产生的一些中间数据。有2个字段:题目和答案,均为备注型。在系统运行过程中,该表中的数据会被不断的更新。 根据系统各模块的实现,系统主要结构即流程图如下所示: 图4-1总体结构图 §5.1 用户登录模块 ● 功能:该模块是检验用户的合法性 
● 窗口设计如下: 图5-1 登录界面 ● 设计思路:当该模块被加载时,从数据库中的登录表中读取已经存在的用户名。将用户名逐一添加到组合列表框的选项中,以供用户选择,(可以避免用户手动输入之繁),在用户选择了某个用户以及在密码框中输入了密码之后(以*显示),在按下“登录”键的时候,系统从数据表中找到对应该用户名的记录,然后检查所输入的密码是否与数据库中的密码一致,若不一致,则提示密码错误,拒绝登录;若一致,则显示该用户以往登录的次数,允许进行后面的操作。 ● 代码实现 (以下代码中‘后为注释) Private Sub Form_Load() login.Picture = LoadPicture(App.Path & "\login2.jpg") Adodc1.ConnectionString= “provider=Microsoft.Jet.OLEDB.4.0;DataSource="+App.Path+\datadb.mdb" Adodc1.RecordSource = "登录" ‘ 数据库连接 Adodc1.Refresh Adodc1.Recordset.MoveFirstDo While Not Adodc1.Recordset.EOF Combo1.AddItem Adodc1.Recordset("用户名") Adodc1.Recordset.MoveNext Loop End Sub Private Sub denglu_Click() Adodc1.Recordset.MoveFirstFor p = 1 To userid Adodc1.Recordset.MoveNext Next If Text1.Text <> Adodc1.Recordset("密码") Then MsgBox "您输入的密码不正确,请重新登录", vbCritical, "错误提示" Else cnt = Adodc1.Recordset("访问次数") + 1 k = MsgBox("祝贺你成功登录 " + Chr(13) + "这是您第" & cnt & "次访问该系统", vbOKOnly, "Congratulations") Adodc1.Recordset("访问次数") = cnt Adodc1.Recordset.update End If If k = 1 Then enter.Visible = True Unload Me Load enter End If End Sub §5.2 系统维护模块 功能:对系统的安全等做一些基本的维护,如添加数据库,修改密码,增加用户等。由于该模块功能只有具有一定权限的管理员才能使用,因此在激活该菜单之前要求输入管理员密码。各具体功能设计如下: ◘5.2.1 新建数据库:用户通过文件对话框选择保存数据库的路径,键入数据库名,完成以后就会在选定的路径下新建一个access数据库。 其实现代码如下: Private Sub newdb_Click( ) CommonDialog1.Flags = 0CommonDialog1.ShowSave newd = CommonDialog1.FileName Set MSAccess = New Access.Application MSAccess.Visible = True MSAccess.NewCurrentDatabase (newd) End Sub 
◘5.2.2 修改密码:窗口启动时,从数据库中读取所有用户名,添加于列表中,要求用户输入原始密码和新密码,若原始密码与数据库中的密码数据一致,则把新密码中值替换数据库中的原始密码字段,保存,若输入的原始密码不正确,则给出出错信息。窗口如图5-2所示: 图5-2 修改密码界面 代码实现同登录类似,在此略。 ◘5.2.3添加用户:通过向文本框中输入用户名和密码向“登录”表中追加一条新的记录,同时设置该字段的“访问次数”值为0。 §5.3 题库管理模块 ● 功能 包括对库中试题的浏览、删除、修改、更新、添加等。 ● 特点 1.难度、题型、分值、章节均可根据学校实际教学使用需要任意设置。 2.提供开放式试题数据库功能,用户可方便的录入、编辑、修改和保存自己的试题和试卷,并且能直接加入本系统的数据库,利用本系统进行统一管理。 窗口设计如下: 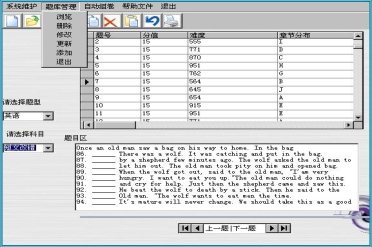
图5-3 题库管理窗口 ◘5.3.1 浏览 当单击“题库管理”下的“浏览”子菜单时,出现类似如上窗口的界面,从左边的组合框中选择科目“英语”及题型,就可以在主窗体中显示相对应的数据库中的内容,它是由adodc1(0..4)5个控件对各题型的数据表进行绑定,然后利用datagrid1(0..4)控件显示出来。由于题目这个备注型字段中的字符较多,不能全部在字段栏里显示,加之题目的内容是用户最为关注的,因此单独设立了对应的题目区,它也由5个文本框text1(0 ..4)实现,当用户选择了题型后,在程序中,通过设置各个datagrid控件及文本控件的Zorder值以达到只向用户展示所选择题型的内容的出现效果。 Private Sub Combo2_Click() i = Combo2.ListIndex Text1(i).ZOrder DataGrid1(i).ZOrder Adodc1(i).ZOrder Adodc1(i).Visible = True End Sub ◘5.3.2删除:单击该子菜单以后,会弹出确认窗口,以免误操作。它将删除当前指向的记录。 Private Sub delete_Click() Dim r As Integer r = MsgBox("确定删除当前记录?", vbExclamation + vbYesNo) If r = vbYes Then i = Combo2.ListIndex Adodc1(i).Recordset.delete Adodc1(i).Recordset.MoveNext If Adodc1(i).Recordset.EOF Then Adodc1(i).Recordset.MoveLast End If End If End Sub ◘5.3.3添加:单击该项后,主窗体中会显示一个新的界面,有5个文本框,用于用户输入题目的属性. ◘5.3.4 更新:在对所要添加的记录数据输入完以后,再单击“更新”,一条新的记录就才添加到数据库中,可以使用“浏览”查看新的数据库结构。 Private Sub update_Click() i = Combo2.ListIndex Adodc1(i).Recordset.AddNew Adodc1(i).Recordset("题号") = CInt(Text2(0).Text) If i = 0 Or i = 4 Then Adodc1(i).Recordset("知识点") = (Text2(3).Text) End If Adodc1(i).Recordset("分值") = CInt(Text2(1).Text) Adodc1(i).Recordset("难度") = Text2(2).Text Adodc1(i).Recordset("题目") = Text2(4).Text Label1.Visible = True Label2.Visible = True Label3.Visible = True Label4.Visible = False Label5Visible = False Label6Visible = False Label7.Visible = False For i = 0 To 4 DataGrid1(i).Visible = True Text1(i).Visible = True Combo1.Visible = True Combo2.Visible = True Text2(i).Visible = False Next i Label3.Visible = True End Sub ◘5.3.5 修改:由于已经把datagrid控件的属性设置为可以修改的,因此可以直接在控件中修改数据,但是要注意的一点是,仅仅在datagrid中修改过的数据并不能保存到数据库中,因此修改完以后需要按“修改”菜单,这样修改过的记录在数据库中才会被更新。 Private Sub modify_Click() i = Combo2.ListIndex Adodc1(i).Recordset.update End Sub §5. 4 自动组卷模块 ◘5.4.1功能: 根据用户输入的题型分布、章节分布以及难度分布等要求,根据一定的组卷策略从试题库中随机抽取出满足条件的试题组成一份使用户满意的试卷。 ◘5.4.2设计思路: 首先由用户选择试卷中知识点的范围,即所属涉及的章节,给出需要的各章节分布、题型分布(各种题型中分值的百分比)和难度分布。章节的选择由具有10个项的组合框给出,用户选定了某个章节以后,该章节就会被添加到一个新的列表中,通过在文本框中输入数值来确定章节分布。题型分布只需在对应文本框中输入值即可。难度有三种级别:容易,中等,难。对应的数值表示所要求的试卷生成后整份试卷中容易、中等和难题的分值,它们对应于试题库中“难度”属性的值。输入要求得到确认后,开始组卷工作,即从试题库中抽取满足条件的试题。根据一定的组卷策略,组卷过程中产生的一些临时数据放在一个临时库文件temp中,同时temp中的数据也要不断的更新,使得最后留在temp库中的数据是满足条件的试题。当完成抽题以后,调用word应用程序,将temp中的记录逐一的写入到word文档中,这样用户就可以利用word提供的一些编辑功能对试题做一些编辑调整和打印存档。 ◘5.4.3组卷策略分析: 组卷策略是指系统进行组卷的方式方法。它是题库系统自动生成有效(对测验目标来说)试卷的关键。组卷策略设计主要涉及成卷要求的数量化、卷面分数分配、库中选题等问题的处理。 本系统主要是依托于随机函数实现,在考虑满足各约束条件间的相互制约的过程中又利用动态优先权和误差平均分配等策略。 随机函数指的是系统vb提供的随机函数,从满足某些检索条件的试题库中随机的抽取一题,之后来判断它的各个属性。若最终随机产生的n个试题中,他们之间的约束条件满足要求,则可以被做为一份试卷的试题。 动态优先指的在组卷过程中先进行大题的选择,如书面表达,短文改错等。在组卷过程中局部的约束条件多达好几种,在本系统中涉及到的有题型的比例,章节的比例以及难度的比例。选中一道题,对应着这些指标中的值就会增加,使它们更接近预定的分值。在选题的开始阶段,不存在约束条件间的牵制问题,因为各项属性都有很大的取值范围。但随着被选题数的增加,取值范围的缩小,矛盾便随之产生,出现了一道待选试题的某项指标中达到了预定值,而其它项指标却超出了范围的现象,尤其是分值较高的大题,到后期很难满足要求,往往会导致选题进行到一定程度的时候,徘徊在某一个状态下,无法继续进行下去的局面,为了避免这中情况的发生,可考虑利用优先权的方法把越不容易选择的试题放在 前面优先选择,而把选择题放在最后选择,主要依靠选择题的选择来平衡各约束属性间的制约。 误差平均分配:理想的组卷结果是各项约束值之间百分之百的满足约束条件,但是事实上,由于随机技术的采用,约束间的互相牵制,以及试题库中题量的限制和属性设置间的重叠等,在组题过程中很难达到理想的状态。如果把条件限制的过于绝对,则有时候往往会因为数分之差,就需要计算机重新不断的筛选,甚至进入无休止的循环状态,永远无法完成抽题,这种代价是不必要的,为了解决上述情况,我们在系统设计的过程中允许约束条件间可以有一定的误差,在总分值满足满分的条件下,它们之间可以在一定的范围内调节。
◘5.4.4 具体实现过程及相应代码: 
窗口界面如下:  组卷过程:在这里先给出窗体加载时的代码,主要是完成一些数据库的绑定: Private Sub Form_Load() Image1.Picture = LoadPicture(App.Path & "\zj.gif") For i = 0 To 4 Adodc1(i).ConnectionString= "Provider=Microsoft.Jet.OLEDB.4.0;Data 1
基于试题库的自动组卷系统 Source=" + App.Path + "\datadb.mdb;" Next Adodc1(0).RecordSource = "选择题" Adodc1(1).RecordSource = "书面表达" Adodc1(2).RecordSource = "短文改错" Adodc1(3).RecordSource = "阅读理解" Adodc1(4).RecordSource = "完型填空" For i = 0 To 4 Adodc1(i).Refresh Adodc1(i).Recordset.Filter = adFilterNone Next Data1.DatabaseName = App.Path & "\tempdb.mdb" Data1.RecordSource = "temp" Adodc2.ConnectionString = "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + App.Path + "\tempdb.mdb" Adodc2.RecordSource = "temp" Adodc2.RefreshData1.DatabaseName = App.Path & "\tempdb.mdb" Data1.RecordSource = "temp" End Sub 1. 首先用户在界面上输入各种约束条件:章节分布、题型分布、难度分布。检查深入无误以后,单击确定按扭(否则可以按“重置”按扭进行重新设置)进行组卷。 2. 组卷。“确定”按扭的代码如下:(之后将给出具体的介绍和解释) Private Sub zujuan_Click() Dim zj As Integer aval(0) = 1 ,aval(1) = 20 aval(2) = 15,aval(3) = 8 aval(4) = 25 fstr = "" For j = 1 To z - 1 szhj(j) = Chr(zhj(j) + 64) fstr = fstr & "章节分布 like '" & szhj(j) & "*'" & "or " Next fstr = fstr & "章节分布 like '" & Chr(zhj(j) + 64) & "*'" L: Data1.DatabaseName = App.Path & "\tempdb.mdb" Data1.RecordSource = "temp" 1
基于试题库的自动组卷系统 Data1.Refresh Data1.Database.Execute ("DELETE * FROM temp") ‘ 清空临时库 Data1.Database.Close Adodc2.Recordset.MoveFirst While Adodc2.Recordset.EOF <> True Adodc2.Recordset.delete Adodc2.Recordset.MoveNext Wend lc = lc + 1 ‘lc 用来记录重复抽取的次数 If lc > 5000 Then msg = MsgBox("抽题失败,请重试", vbOKCancel) If msg = 1 Then lc = 0 GoTo L Else End ‘用户没有选择重试,则终止程序 End If End If etotalf = 0 ‘etotalf 、mtotal、htotal分别表示 mtotalf = 0 所有已抽取的题目中的容易、中 htotalf = 0 等、较难的总分值 For s = 1 To z zhjf(zhj(s)) = 0 ‘zhjf() 数组表示所选择的章节 Next For i = 1 To 4 Adodc1(i).Recordset.Filter = fstr ‘只打开所选择章节内的试题记录 cnt(i) = Adodc1(i).Recordset.RecordCount tl(i) = CInt(Text3(i).Text) \ aval(i) ‘tl( )表示在最终的试卷中某 yushu = CInt(Text3(i).Text) Mod aval(i) 题型的题量 If yushu > aval(i) \ 2 Then tl(i) = tl(i) + 1 End If For t = 1 To tl(i) Randomize vth(i, t) = Int(Rnd * cnt(i)) + 1 Adodc1(i).Recordset.MoveFirst For n = 1 To vth(i, t) – 1 ‘将记录移到随机数所对应的 Adodc1(i).Recordset.MoveNext 记录上 Next timu = Adodc1(i).Recordset("题目") Adodc2.Recordset.AddNew Adodc2.Recordset("题目") = timu ‘将找到的记录里的题目和答 daan = Adodc1(i).Recordset("答案") 案字段写进临时库文件中的题目 Adodc2.Recordset("答案") = daan 和答案字段中 Adodc2.Recordset.update nandustr = Adodc1(i).Recordset("难度") echar = Mid(nandustr, 1, 1) ‘取得难度字段各位上的字符 mchar = Mid(nandustr, 2, 1) hchar = Mid(nandustr, 3, 1) e(i, t) = CInt(echar) ‘类型转换 m(i, t) = CInt(mchar) h(i, t) = CInt(hchar) zj = Asc(Adodc1(i).Recordset("章节分布")) – 64 ‘ 将章节中的A~J答应 zhjf(zj)=zhjf(zj)+Adodc1(i).Recordset(’’分值’’) 为1~10 Next Next ‘大题抽取完毕 For i = 1 To 4 For t = 1 To tl(i) etotalf = e(i, t) + etotalf mtotalf = m(i, t) + mtotalf htotalf = h(i, t) + htotalf Next Next xetotalf = CInt(Text2(0).Text) – etotalf ‘ xetotal表示还需要 xmtotalf = CInt(Text2(1).Text) – mtotalf 选择的容易的题目的分值 xhtotalf = CInt(Text2(2).Text) – htotalf For j = 1 To z zhjxtotalf(zhj(j)) = zhjtotalf(zhj(j)) - zhjf(zhj(j)) ‘判断是否有章节 If zhjxtotalf(zhj(j)) < 0 Then 中的分值已经超过了要求的值 GoTo L End If Next xtotalf = xetotalf + xmtotalf + xhtotalf If xtotalf < 0 Then GoTo L End If Adodc1(0).Recordset.Filter = fstr ‘开始选择题的抽取 For j = 1 To z zhjfx(j) = 0 Next cnt(0) = Adodc1(0).Recordset.RecordCount tl(0) = xtotalf \ aval(0) For t = 1 To tl(0) Randomize vth(0, t) = Int(Rnd * cnt(0)) + 1 Adodc1(0).Recordset.MoveFirst For n = 1 To vth(0, t) - 1 Adodc1(0).Recordset.MoveNext Next timu = Adodc1(0).Recordset("题目") Adodc2.Recordset.AddNew Adodc2.Recordset("题目") = timu nandustr = Adodc1(0).Recordset("难度") echar = Mid(nandustr, 1, 1) mchar = Mid(nandustr, 2, 1) hchar = Mid(nandustr, 3, 1) e(0, t) = CInt(echar) m(0, t) = CInt(mchar) h(0, t) = CInt(hchar) p = Asc(Adodc1(0).Recordset("章节分布")) - 64 zhjfx(p) = zhjfx(p) + Adodc1(0).Recordset("分值") Next xe = 0 xm = 0 xh = 0 For t = 1 To tl(0) xe = e(0, t) + xe xm = m(0, t) + xm xh = h(0, t) + xh Next For q = 1 To z If Abs(zhjxtotalf(zhj(q)) - zhjfx(zhj(q))) > 5 Then b = True Exit For End If Next If Abs(xe - xetotalf) > 10 Or Abs(xm - xmtotalf) > 10 Or Abs(xhtotalf - xh) > 10 GoTo L 'Else msgc = MsgBox("已经成功完成抽题") If msgc = 1 Then editcmd.Enabled = True End IfEnd If End Sub 1
基于试题库的自动组卷系统 部分解释如下:其中的aval0~aval4 表示对应的选择题、书面表达、短文改错、阅读理解、完型填空中每题的平均分数。数组zhj(1 to 10)由combo1(即章节选择列表框)的代码中定义zhj(z + 1) = Combo1.ListIndex + 1,z =z+1;用来表示所选中的章节,取值范围是1~10 例如zhj(2)=4 表示选择的第2种章节类型是第4章。fstr 用来做过滤变量,即若用户选择了第一、三、八章3个章节的时候,在后面的组卷过程中,只是从这三章的试题中抽取试题,而不是从整个数据表中搜索,大题即完型填空、书面表达、短文改错、阅读理解的抽取试题方法相同:text3(i)中得到的数值为对应的题型I的试题总分值。tl(i)表示为了满足text3(i)的条件需要抽取的题量。利用随机函数vth(i, t) = Int(Rnd * cnt(i)) + 1 依次从试题库中抽取试题,cnt(i)是所选中章节中的题型I的总题量,vth(I,t)表示题型I中 第t题在数据表(经过filter以后的表)中的位置,然后数据表中的记录从第一条到最后一条之间扫描,找到对应的记录vth(I,t)的位置,利用recordset(“题目”)和recordset(“答案”)的方法把所找到的记录中的题目和答案字段复制到临时库文件temp中(它由程序中的adodc2控件绑定)。然后把记录的其他一些属性保存起来,后面将用它们来判断约束条件的成立与否。具体提取的属性值如下:难度----在数据库中我们已经解释过“难度”字段的含义,现在就用三个变量来分别提取该字段中的三个位的值,e(i, t) = CInt(echar)表示所选取的题型I的第t题的难度属性中对应的容易的分值,m(i, t) 、h(i, t)则依次答应中等和较难的分值;章节----因为在数据库中利用A~J表示章节,所以在程序中需要利用Asc(Adodc1(i).Recordset("章节分布")) – 64 把属性中的A~J转化成相对应的1~10, 使之与zhjf(1 to10)中下标匹配,zhjf()表示已抽取的题目中某章节占的总分数,例如zhjf(2)=30,表示第2章已抽取的总分数为30分。当大题一次遍历抽取之后,把所有已抽取的题目中的容易、中等、较难的分值做累加,用xetotlaf、metotalf、htotalf表示。xetotalf=text2(0)-etotalf 、xmtotalf=text2(1)-mtotalf、xhtotalf=text2(2)-htotalf得出需要从选择题题抽取的题目难度分布。zhjtotalf(1to10 )表示的是在界面中输入的对各章节分布的要求,用代码中的zhjtotalf(zhj(j)) - zhjf(zhj(j)) 就可以求得在选择题中可以在各章节中抽取的分数,用zhjxtotalf()表示,若数组zhjxtotalf()中的某一个值小于零,则重新开始大题的抽题。因为这意味着在抽取大题的过程中,某个章节的比重已经超出了预定的值。最后开始选择题的抽取。选择题的随机抽取过程与大题一致,在此不再解释,主要介绍一下涉及最后一些约束条件判断的变量。zhjfx() 表示实际抽取出来的选择题中各章节的分数,Abs(zhjxtotalf(zhj(q)) - zhjfx(zhj(q)))是否大于5作为判断本次随机抽取过程有效性的标准之一,若大于5,则视抽题失败,重新开始新一轮的选择;若小于则再判断其他条件是否满足。用xe、xm、xh表示实际抽取出来的选择题中各难度的值的分布。用Abs(xe - xetotalf) > 5来判断实际抽取的选择题与要求的在容易题上的误差,类似有Abs(xm - xmtotalf) > 5 、Abs(xhtotalf –xhtotalf)的定义。如果以上三个限制条件中有一个不满足,则视为抽题失败,重新开始随机抽题过程,若总的循环次数超过了某个值,如5000,则视无法按预定义要求组卷,要求退出系统重新设置参数。在又一轮的循环之前,有一项需要做的工作是把temp数据表中的数据清空,因为这都是些中间数据,它们已经被判定为不满足条件的,继续存储在表中,会给后面的组卷工作带来错误,因此要删除。当出现提示“完成抽题”的提示后,单击确定,界面上的“编辑试卷”按扭置为可编辑,进入组卷的最后一个环节。 ◘5.4.5 试卷编辑。 将临时库文件中的试题记录逐条的读入word文档中。具体操作是:先建立一个word OLE自动化对象 ,利用其的insert方法将记录从数据表中读取出来插入到文档中。在此过程中,通过判断tl()的值在适当的时候插入题型的标题和题号,如在选择题试题插入完之后应该插入一行文本“完型填空”。用户可以对其进行试题做一些调整以及打印、存档。实现代码如下: Private Sub editcmd_Click() For c = 0 To 4 ttl = ttl + tl(c) Next bh = 1 Dim objWord As Object Set objWord = CreateObject("word.basic") objWord.appshow objWord.filenew Adodc2.Recordset.MoveLast objWord.Insert "第一大题 选择题" & Chr(13) For j = 1 To ttl If j <= tl(0) Then objWord.Insert "(" & bh & ")" & " " & Adodc2.Recordset("题目") & Chr(13) Else objWord.Insert Adodc2.Recordset("题目") & Chr(13) End If If j = tl(0) + tl(4) Then objWord.Insert "第三大题 阅读理解" & Chr(13) If j = tl(0) + tl(4) + tl(3) Then objWord.Insert "第四大题 短文改错" & Chr(13) If j = tl(0) + tl(1) + tl(3) + tl(2) Then objWord.Insert "第五大题 书面表达" & Chr(13) Adodc2.Recordset.MovePrevious bh = bh + 1 Next End Sub
结束语: 自动组卷并不是一个新的领域,但它仍处在需要不断的完善的阶段之中。由于各个学科的不同,基于试题库的自动组卷系统在数据库设计等方面会有些许的差异,本系统的实现实质上是抛张引玉。本文介绍和完成了一个具体的组卷系统的开发,它具有一定的实际应用价值,然而由于在时间、能力、技术等诸方面的不足,在算法优化和库结构的设计上还有一些有待于改进的地方,还有许多功能有待于日后来增强。这是本人第一次真正的做软件开发,在一次次的发现问题、解决问题的过程中,学到了许多专业知识以及处理事务的方法,为以后的学习和工作积累了丰富的经验,这是本人认为比这个完成软件更具有意义价值的。
| 









 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 收藏
收藏 淘帖
淘帖 顶
顶 踩
踩

