说起网络爬虫,我孤陋寡闻了,听上去像蠕虫,就以为是网页病毒来着,度娘了下,原来是抓取网页信息的程序或是脚本 。最近又要交个无题的作业,加上前不久学长都在某某论坛里看就业信息,所以一来劲就做了个就业信息挖掘机。 。最近又要交个无题的作业,加上前不久学长都在某某论坛里看就业信息,所以一来劲就做了个就业信息挖掘机。
首先看看这个网页,地址我就不说了,大家都懂得。页面布局同大多的论坛差不多:一个首页、尾页选项,上一页、下一页选项,跳转选项,以及有针对性的板内查询选项。要找到有利的信息,当然就要看这个查询功能了,我可不想天天像跟美剧的一样时刻关注,也许是时候未到吧?
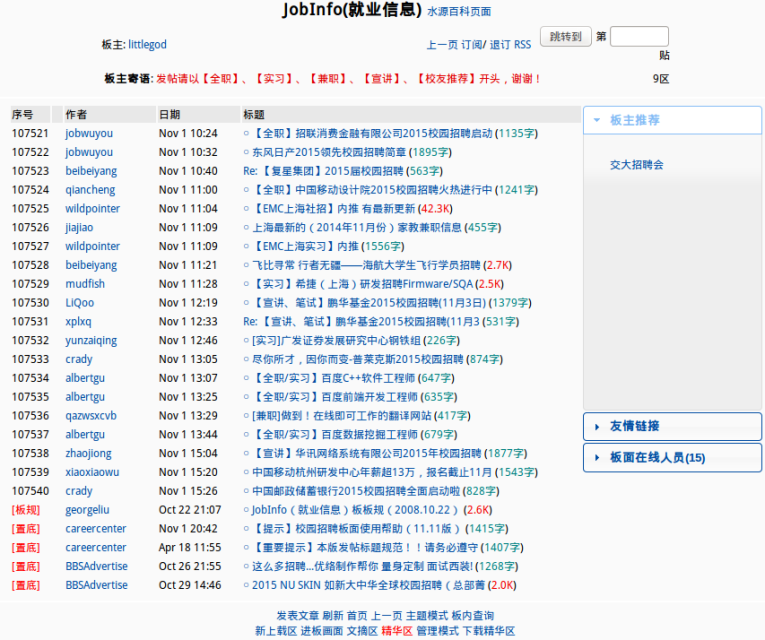
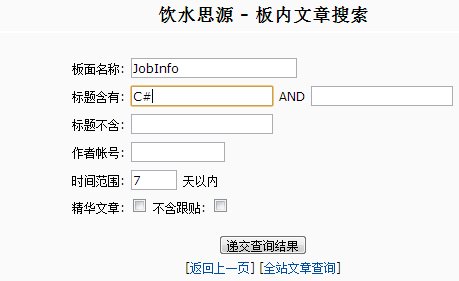
进入查询页面,这让我情何以堪,只能按标题、作者、时间来搜!那么问题就来了,木有关键词?木有模糊搜索?简直和在页面上看标题的效率差不多。。。对于改进,最初的想法是做一个搜索的引擎,可以无监督学习,按给定的关键词给出相关联的结果,就像成语接龙一样,由近及远,但细想一下,要这样绝不是一两个星期就可以解决的,所以就退一步,不搞搜索了,我把这些信息的时间、标题、链接以及主要的关键词都采集出来,以此帮助我筛选信息。
[color=#f79646,strength=3)"]//***分析*******************************************************************************************************************************//
说做就做,首先对于网页,我首选脚本提高程序效率,不搞花哨的UI,脚本语言目前只会Python。在Python下写网络爬虫,有个很方便的网络抓取框架:Scrapy。下面是Scrapy的数据流程图。
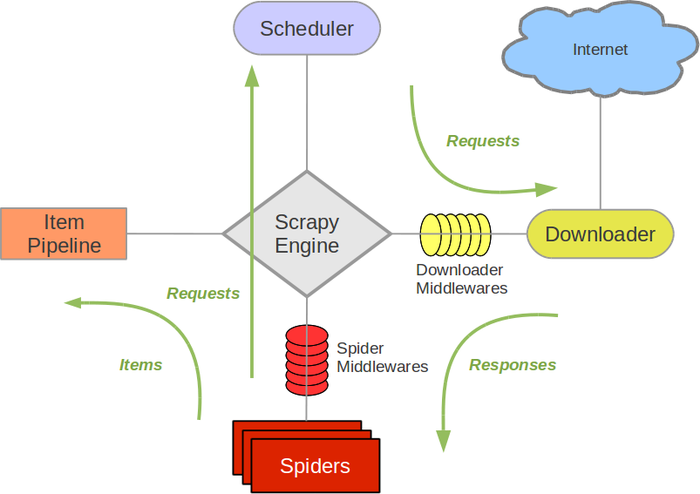
一开始,由Schedule将起始的URL交给Download处理,下载完后给Spider分析,Spider分析出下一链接就交给Schedule,分析出要提取的内容就交给ItemPipeline保存处理。
其次,该网页出现了中英文。对英文分词很简单,因为有空格及split()函数,在英文下的词性检测算法也较多;关键在中文上,网页源码采用JavaScript编写,GB2312编码,在抓取中可能出现乱码问题,还有关键词,汉字真是博大精深,同样的词在不同语境下有不同的意思,想了好久,决定直接用jieba中文分词组件,只要有自定义的词库,调用简单,但肯定是会有各种抓取不准的问题。
最后,对于无监督学习也想了一些思路,要一个较为智能的学习,首先要有一个正确的文本集,可以考虑聚类,比如:Apriori算法、FP-growth算法;然后就是在学习的基础上分类,SVM算法、AdaBoost元算法;大数据需要降维,PCA、SVD都可以,还可以高大上的分布式。 当然这也仅限为思路,说说的。 当然这也仅限为思路,说说的。
[color=#f79646,strength=3)"]//***实践********************************************************************************************************************************//
由于没有在windows下成功搭建起Python开发平台的组件,以及eclipse,所以转向Linux,命令行一下就ok了,所以整个爬虫环境搭建在Ubuntu 14.04下。
1)新建一个爬虫工程:命令行# scrapy startproject jobSearch
新建后出现如下信息及scrapy.cfg、jobSearch文件夹;在jobSearch文件夹下有items.py(告诉爬虫抓取的目标),pipelines.py(保存抓取结果),settings.py(用于爬虫的配置),spiders(文件夹为爬虫的核心目录,完成抓取功能)
2)在python_save/jobSearch/下新建文件夹dict:其为关键词(集合了自己的专业词汇以及搜狗输入法的专业相关词汇,14万左右)、停用词集;
在python_save/jobSearch/下新建文件jobSearchAdv.py:用于网页链接里的文本10个关键词的提取。源码大致如下:
USAGE="usage: python jobSearchAdv.py [file name.json]"
parser=OptionParser(USAGE)
opt, args=parser.parse_args()
if len(args)<1:
print USAGE
sys.exit(1)
file_name=args[0]
data=[]
#read info.json to get the big data
def readJSON(fname):
with open(fname) as f:
for line in f:
data.append(json.loads(line))
data.sort(reverse=True)
#to find the keywords
def findKeywords(data):
jieba.analyse.set_stop_words("./dict/stop_words.txt")
jieba.analyse.set_idf_path("./dict/mydict.txt.big")
# jieba.analyse.set_idf_path("myidf.txt.big")
for i in range(len(data)):
try:
detailURL=urllib2.urlopen(data['detailLink']).read().decode('gbk')
detail=re.findall(u"标 题: (.*?)--", detailURL, re.S)
tags=jieba.analyse.extract_tags(detail[0],10)
data['keywords']=", ".join(tags)
except:
data['keywords']="?"
continue
readJSON(file_name)
findKeywords(data)
subdata="\r\n"
for item in data:
subdata+="insert into jobinfo (catalog, publishTime, name, detailLink, keywords) values"
subdata+="('%s','%s','%s','%s','%s');\r\n" %(item['catalog'], item['publishTime'], item['name'], item['detailLink'], item['keywords'])
file_object=codecs.open('detail.sql', 'w', encoding='utf-8')
file_object.write(subdata)
file_object.close()
print "success"
3)在python_save/jobSearch/jobSearch下编写items.py:其中catalog为信息编号,publishTime为信息发布时间, name信息标题 ,detailLink详细链接,keywords为关键词。
class JobsearchItem(scrapy.Item):
# define the fields for your item here like:
catalog = scrapy.Field()
publishTime = scrapy.Field()
name = scrapy.Field()
detailLink = scrapy.Field()
keywords = scrapy.Field()
在python_save/jobSearch/jobSearch下编写pipelines.py:
class JobsearchPipeline(object): def __init__(self):
# self.file=codecs.open('info.csv', 'w', encoding='utf-8')
self.file=codecs.open('info.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item), ensure_ascii=False)+ "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
4)在python_save/jobSearch/jobSearch/spiders下新建jobInfo.py,这里爬虫的核心程序:
class JobSpider(CrawlSpider):
"""docstring for JobSpider"""
allowed_domains=["sjtu.edu.cn"]
start_urls=[
"http://bbs.sjtu.edu.cn/bbsdoc?board=jobInfo",
]
rules=[
Rule(sle(allow=("/bbsdoc,board,JobInfo,page,53\d{2}")), follow=True, callback='parse_item')
]
def parse_item(self, response):
items=[]
sel=Selector(response)
#get "http://bbs.sjtu.edu.cn/"
base_url=get_base_url(response)
#get the detail of current url
for sites_even in sel.xpath('//table[@border="0"]//tr/td'):
namex=sites_even.xpath('a[contains(@href, "html")]/text()')
if str(namex) != "[]":
item=JobsearchItem()
item['catalog']=sites_even.xpath('../td[1]/text()').extract()[0]
url_detail=sites_even.xpath('a[contains(@href, "html")]/@href').extract()[0]
item['detailLink']=urljoin_rfc(base_url, url_detail)
item['name']=namex.extract()[0]
item['publishTime']=sites_even.xpath('../td[4]/text()').extract()[0]
item['keywords']=""
items.append(item)
info('parsed '+str(response))
return items
def _process_request(self, request):
info('process '+str(request))
return request
这样一个爬虫的基本功能得以实现!
[color=#f79646,strength=3)"]//***运行测试****************************************************************************************************************************//
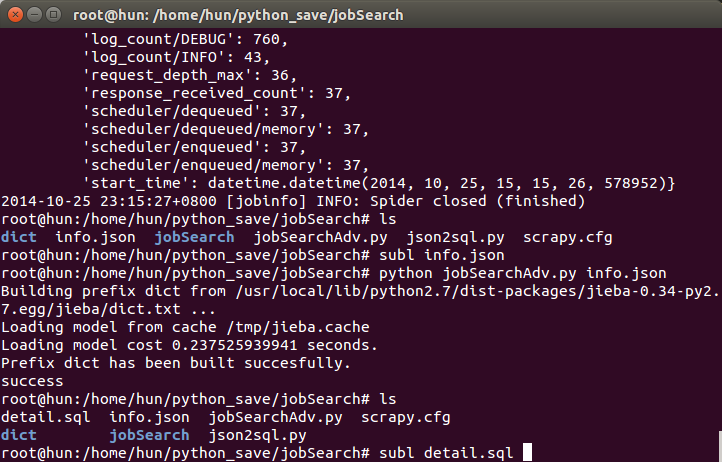
1)命令行:# scrapy crawl jobinfo,生成如下信息和info.json文件(包含:关键词(无),序号,详细链接,标题,日期)
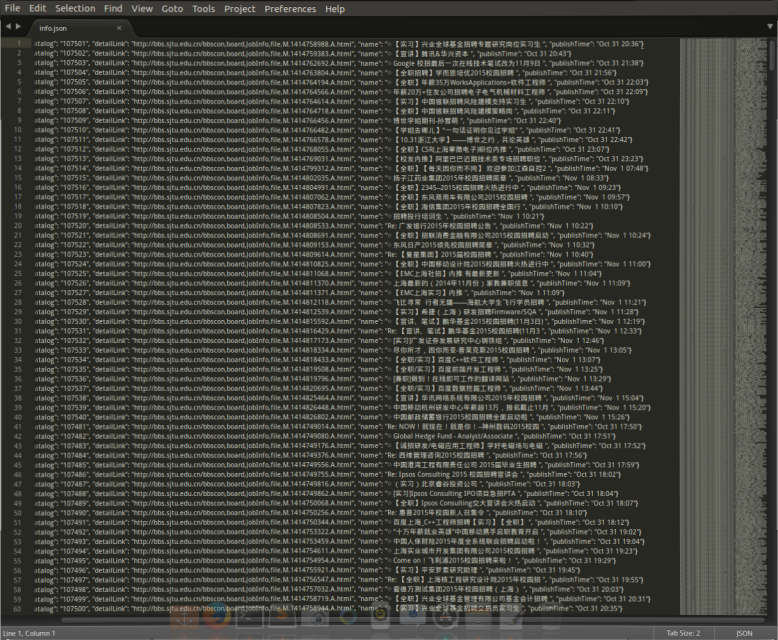
sublime查看info.json文件,如下,发现是无序的,无关键词。
2)命令行:# python jobSearchAdv.py info.json,对info.json各标题链接进行关键词提取,生成文件detail.sql。出现如下信息和生成文件。
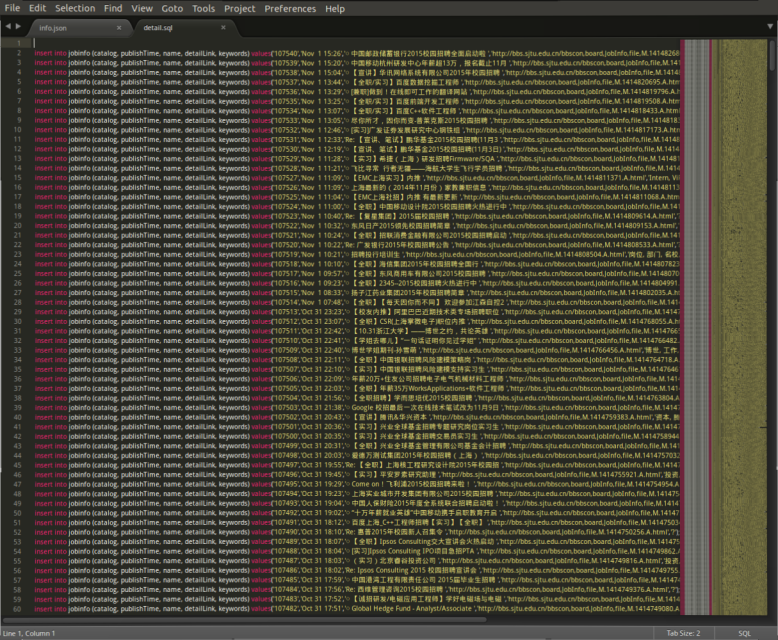
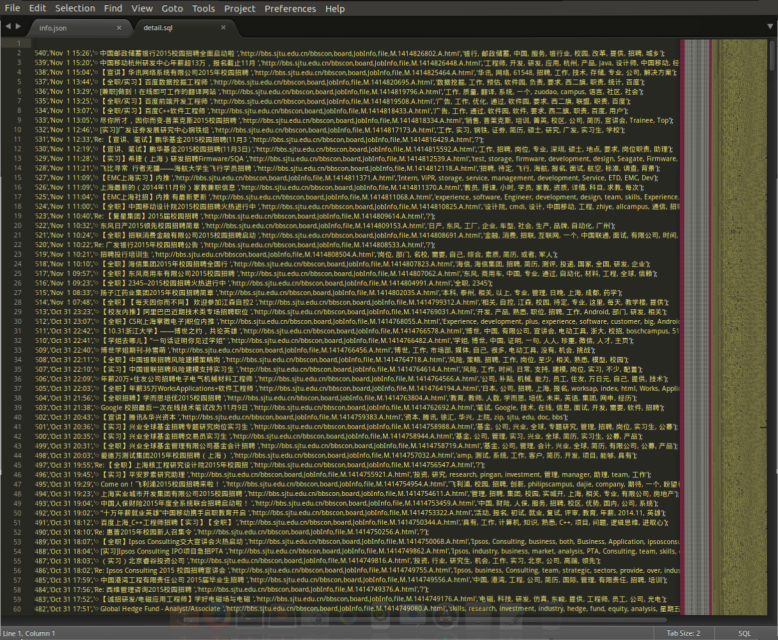
sublime查看detail.sql文件:
[color=#f79646,strength=3)"]//***样例****************************************************************************************************************************//
detail.sql这个文件就是最终结果了,列出了10个关键词、标题、时间等信息。
如下的一个小截图。“中国移动杭州研发中心年薪超13万,报名截止11月”,至少我看得懂它的关键词:“工程师,开发,研发,应用,杭州,产品,Java,设计师,中国移动,经理助理”。
但细看,在列出的10个关键词中还是存在问题的,比如下一条,“华讯网络系统有限公司2015年校园招聘”中出现了“61548”,“专业”等无意义词~

|