
自制汉字取模软件,学嵌入式的要看(王挺帅)建议无协成员看
汉字点阵取模 16*16点阵 转载请注明出处
学嵌入式开发这么长时间来一直都在使用别人的取模软件,很希望有自己的取模软件。
今天晚上读了一下汉字编码和点阵的文章做程序如下。希望对无协嵌入式开发有帮助
在计算机中英文一般使用 ASCII 码来表示,而汉字编码使用的是扩展 ASCII 码,用两个ASCII码来表示一个汉字。一个ASCII码占用一个字节,所有在存储时英文是占用一个字节,而汉字占用两个字节。
扩展 ASCII 码:也就是 ASCII 码的最高位是1的 ASCII 码,一个汉字由两个扩展 ASCII 码组成,第一个扩展 ASCII 码用来存放区码,第二个扩展 ASCII 码用来存放位码。
区位码:在 GB2312-80 标准中,将所有的汉字分为94个区,每个区有94个位可以存放94个汉字,形成了人们常说的区位码,这样总共就有 94*94=8836 个汉字。
点阵字库:汉字点阵数据就是按照这个区位的顺序来存放的,也就是最先存放的是第一个区的汉字点阵数据,在每一个区中有是按照位的顺序
来存放的。
汉字机内码、国标码和区位码三者之间的关系为:区位码(十进制)的两个字节分别转换为十六进制后加20H得到对应的国标码;机内码是汉字交换码(国标码)两个字节的最高位分别加1,即汉字交换码(国标码)的两个字节分别加80H得到对应的机内码;区位码(十进制)的两个字节分别转换为十六进制后加A0H得到对应的机内码
国标码 由两个扩展ascii码组成
汉字区位码的存放实在扩展 ASCII 基础上存放的,并且将区码和位码都加上了32,然后存放在两个扩展 ASCII 码中。具体的说就是:
汉字的
第一个扩展ASCII码 = 128+32 + 汉字区码
第二个扩展ASCII吗 = 128+32 + 汉字位码
第二个扩展ASCII吗 = 128+32 + 汉字位码
程序要用的字库HZK16
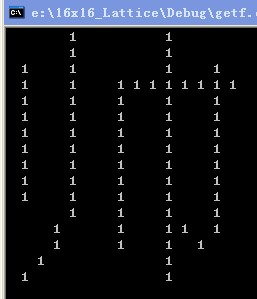
程序如下
#include "stdio.h"
#include<iostream>
using namespace std;
void getCode(unsigned char str[],unsigned char data[]);
void main()
{
unsigned char str[] = {"王挺帅"};
unsigned char data[32];
for(int m = 0;m <1;m++){
getCode(str+m*2,data);
for (int j=0 ;j<32;j+=2)
{
// char 转换成二进制输出
for(int t = 7;t>=0;t--)
{
if((data[j]>>t)&1)
printf("%d ",(data[j]>>t)&1);
else
printf(" ",(data[j]>>t)&1);
}
for(int t = 7;t>=0;t--)
{
if((data[j+1]>>t)&1)
printf("%d ",(data[j+1]>>t)&1);
else
printf(" ",(data[j+1]>>t)&1);
}
cout<<endl;
}
}
getchar();
}
//返回点阵数组
void getCode(unsigned char str[],unsigned char data[]){
char font_file_name[] = "HZK16"; // 点阵字库文件名
int font_width = 16; // 单字宽度
int font_height = 16; // 单字高度
int start_offset = 0; // 偏移
long offset;
FILE *fp;
fp = fopen(font_file_name, "rb");
int offset_size = font_width * font_height / 8;
int string_size = font_width * font_height;
int i=0;
if (str[i] > 160)
{
// 先求区位码,然后再计算其在区位码二维表中的位置,进而得出此字符在文件中的偏移
offset = ((str[i] - 0xa1) * 94 + str[i+1] - 0xa1) * offset_size;
i++;
}
else
{
offset = (str[i] + 156 - 1) * offset_size;
}
// 读取其点阵数据
fseek(fp, start_offset + offset, SEEK_SET);
fread(data,sizeof(char), offset_size,fp);
fclose(fp);
}