
在C/C 中经常需要进行存储器的操作,关于数据如何在存储器中存储的问题也是非常重要的,如何在保证数据量(信息量)的同时又保证数据的存储量最小,乍一听感觉没什么好讨论的。但是作为学习嵌入式的必须要明白数据的存储是与数据的结构存在密切联系的,特别是结构体中的内存分配问题。
首先应该明白基本的类型在内存中的大小,char型一般占有1个字节,int型一般占有4个字节,double型一般占有8个字节,short 则占有2个字节(当然也会存在一定的变化,具体情况依据编译器决定)。我们都知道C语言的结构体是一个不同类型数据的集合。那么一个结构体到底占多少存储空间呢?
首先应该意识到C语言的存储存在一定的特殊性。在C语言的结构体中需要主要的是数据存储的对齐方式。对齐主要是为了方便数据的访问,提高计算机的处理速度,但是对齐会导致内存空间的浪费,这些浪费对于大内存空间的设备而言,没什么必要,但是对于嵌入式系统而言会造成大量的浪费。
在32bits的系统中对一个寄存器(32bits)的访问直接访问,但是对于寄存器中某一个字节的访问反而觉得很不方便,因此如果只是单个字节的访问反而增加了系统的负担。对一个寄存器的访问可以通过一个起始地址来实现,但是我们在很多CPU的用户手册中都会发现,寄存器的起始地址都能被4整除,这就是为了提高计算速度而采取的一些默认的方式。一个寄存器一般而言占有4个bytes,那么对下一个寄存器的访问只需要在原来的地址基础上加上4个 bytes即可。
对齐的基本作用就是提高系统的功能,特别是访问存储器的能力得到提高。
对齐在使用中有较多的意义。基本的使用原则:
1、对齐是为了提高系统的访问速度,一般基本的对齐原则是按着最大的基本类型的长度进行对齐,较小的元素可以几个组合起来填充一段对齐内存,实现基本的对齐,但是需要满足条件2。
2、结构体中的元素也要满足一定的分布条件,就是元素的存储起始地址要满足能够整除该元素类型的长度。
3、在结构体中存在结构体的情况下,也只是按着结构体中最大的基本类型长度对齐(包含内部结构体中的最大基本类型长度)。
在不同的编译器之间也存在一定的差别。在linux中最大的对齐长度是 4个字节,也就是如果结构体中的最大的基本类型长度是大于4的,那么也按着4对齐,同时不会按着结构体中最大的基本类型的长度对齐,伴随着最大基本类型元素的起始地址也不再满足能够被最大元素类型长度对齐的原则,而是满足整除4即可。但如果结构体中最大的基本类型长度小于4,那么按着最大的基本类型长度对齐
但是在windows中基本上都是按着最大的基本类型长度进行对齐,和一般的原则相似。
这边只是我的一些理解其中具体的要具体分析,在实际中建议将最大基本类型的元素放在开始的地方,然后将其他的数据按着一定的规律(能否组合起来满足对齐条件等)定义结构体,这个规律要根据实际情况分析。
下面通过基本的代码进行演示:
- #include<stdio.h>
- #include<stdlib.h>
- struct aa{
- char a;
- double b;
- short c;
- };
- struct bb
- {
- double a;
- short b;
- char c;
- };
- struct cc
- {
- struct bb s1;
- char s2;
- };
- struct dd
- {
- struct aa s1;
- char s2;
- };
- #pragma pack(1)
- struct ee
- {
- double a;
- short b;
- char c;
- };
- struct ff
- {
- char a;
- double b;
- short c;
- };
- #pragma pack()
- struct gg
- {
- char a;
- };
- struct jj
- {
- char a;
- short b;
- };
- int main()
- {
- printf("double size is %d %d %d\n",sizeof(double),sizeof(short),sizeof(char));
- printf("size of s1 = %d\nsize of s2 = %d\n",sizeof(struct aa),sizeof(struct bb));
- printf("size of t1 = %d\nsize of dd = %d\n",sizeof(struct cc),sizeof(struct dd));
-
- printf("size of struct ee = %d\nsize of struct ff = %d\nsize of struct gg = %d\nsize of struct jj = %d\n",
- sizeof(struct ee),sizeof(struct ff),sizeof(struct gg),sizeof(struct jj));
- exit(0);
- }
在linux下的结果:
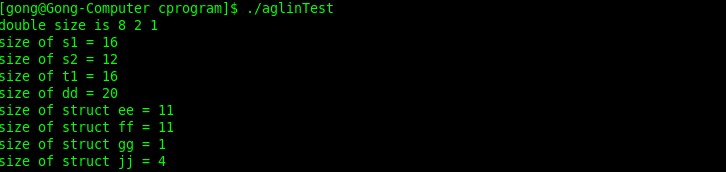
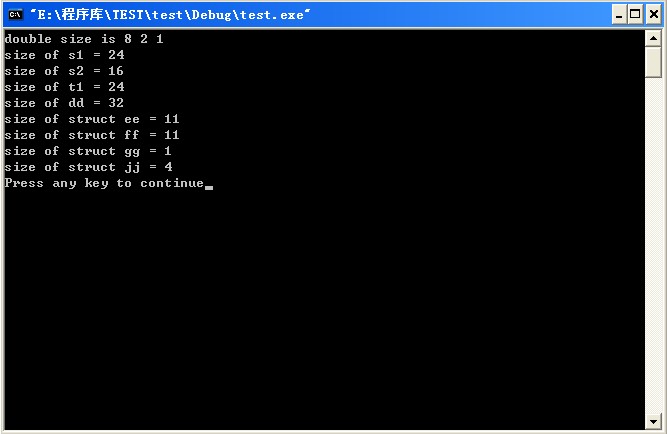
在windows下的结果:
在linux下的存储形式,其中黑色包围起来的才是我们的存储空间白色的部分是保留区域,通过下面的两幅图就可以知道其中的一些道理,知道其中所谓的完成一样的功能,保证存储空间最小:

在windows下的存储形式,其中黑色包围起来的才是我们的存储空间白色的部分是保留区域:

从上面的几个图片可以知道在C语言中的内存分布是比较复杂的。一定要注意存储的对齐形式,这样才能了解其中的分布规律。当然了上面的形式都只是在小端处理器模式下的存储形式,对于大端也有类似的情况,只是存储的位置不一样,但是内存的大小是相同的。
结构体的定义不能是随便的,如果考虑好对齐关系能够节省大量的存储空间。实现效率和存储空间的折中。虽然#pragma pack(n)等能够改变其中的对齐方式,不过建议不要随便改动,可能得不偿失。